1. 概述与目标
本指南目标是通过实际测量与数据分析,将“地域(数据中心位置、PoP分布)”与“网络线路(延迟、丢包、AS路径、互联)”结合,得出泰国云服务器供应商的可比排行并给出可复现步骤。
最终输出包括:采集脚本、测试命令、评分模型、自动化监控与可视化结果,便于运维或采购决策。
2. 准备工作与工具清单
先准备至少一台可远程访问的测试主机(建议在中国、香港、新加坡、美国等多个地区),并安装以下工具:ping、traceroute(或traceroute6)、mtr、iperf3、curl、openssl、speedtest-cli、jq。
推荐线上服务:RIPE Atlas(测点)、各云商Looking Glass、PeeringDB、BGPlay/RouteViews、Team Cymru whois。还需表格工具(Excel/Google Sheets)与可视化工具(Grafana/Kepler/Google My Maps)。
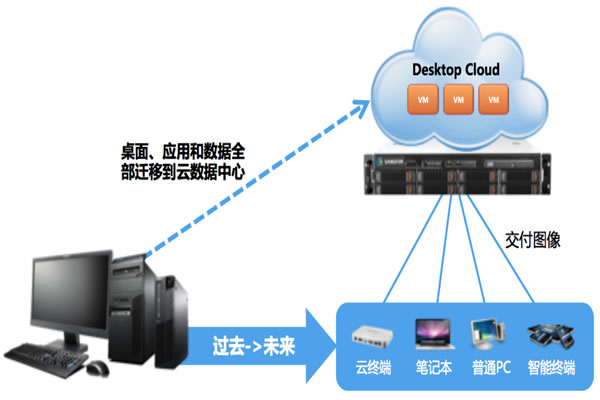
3. 收集泰国云服务商与地域信息
步骤1:列出目标供应商(如:AIS、True、NT/旧TOT、泰国本地云与国际云在泰PoP)。可通过官网、数据中心页面和PeeringDB确认PoP与ASN。
步骤2:记录每个PoP的地理坐标、城市(曼谷、清迈、普吉等)、机房机架、支持的链路类型(100G/10G/5G)与对外带宽、是否在本地IXP交换。
4. 路由与延迟数据采集(实操)
步骤1:从各个测试点执行ping与traceroute,保存为CSV。示例命令:ping -c 20 <目标IP>;traceroute -n <目标IP>或使用mtr --report -c 100 <目标IP>并保存输出。
步骤2:使用RIPE Atlas或自有VPS,在至少5个不同地理位置重复测试,保证结果具有代表性。记录平均延迟、最大延迟、丢包率与跳数。
步骤3:分析traceroute的每一跳,注意最后几跳是否通过本地ISP或出境链路,以及是否出现高延迟跃点(>50ms突增)。
5. 带宽与吞吐量测试(实操)
步骤1:使用iperf3测试TCP/UDP吞吐量。在云服务器上运行:iperf3 -s,客户端执行:iperf3 -c
步骤2:通过HTTP下载测试真实业务吞吐:curl -w "@curl-format.txt" -o /dev/null -s "http://
步骤3:用speedtest-cli补充ISP到云的端到端速率数据,并记录多时段(高峰/非高峰)结果。
6. BGP/AS路径与互联关系分析
步骤1:用whois或Team Cymru查询目标IP的Origin AS:whois -h whois.cymru.com " -v
步骤2:检查PeeringDB上该ASN的交换点(IXPs)与互联数量。互联越多、直连到本地运营商越多,通常到达终端的延迟与丢包更小。
步骤3:用多个Looking Glass运行traceroute/route-server查询以验证从不同运营商看路由的差异,识别是否存在绕行国际中转导致的延迟。
7. 数据归一化与评分模型(Q&A)
问:如何把延迟、丢包、带宽、PoP覆盖等不同指标统一到一个可比较的分值?
答:先对每个指标做归一化到0-100,例如延迟越小分越高:score_latency = max(0, 100 - (avg_ms / 5))(示例);带宽按百分位归一;丢包按反比归一(0%丢包=100分)。再按权重合成总分:总分 = 0.35*延迟分 + 0.20*丢包分 + 0.20*带宽分 + 0.15*PoP分 + 0.10*互联分。权重可根据业务(比如游戏更重延迟)调整。
8. 自动化采集与可视化(Q&A)
问:如何实现长期自动化测试并把结果做成可视化看板?
答:在多测点上用cron定时执行脚本(bash/python)收集ping/mtr/iperf3结果,输出JSON并推送到Prometheus(或直接写入InfluxDB)。用Grafana构建仪表盘展示延迟、丢包、历史趋势与地图视图。地理可视化可导出GeoJSON并用Kepler或Google Maps展示PoP与平均延迟热力图。
9. 综合地域与线路得出最终排行(Q&A)
问:怎样把地域因素(距离、PoP覆盖)与线路因素(路由质量、互联)结合得出最终供应商排行?
答:第一步用归一化分得到每个维度分数;第二步按业务需求定义权重(例如:Web应用延迟权重30%,带宽权重25%,可用性20%,成本15%,PoP覆盖10%);第三步把各个PoP按地理接近度与本地路由质量合并(若某供应商在目标城市有PoP且直连本地ISP,加分)。最后根据总分排序并对靠前候选做人工复核(查看合同条款、SLA、故障历史)。输出最终报告含得分细项、建议和可替代方案。